
俄羅斯:將審查iPhone等外國公司設備 保數據安全
iPhone和特斯拉都屬于在各自領域領頭羊的品牌,推出的產品也也都是數一數二的,但對于一些國家而言,它們的產品可靠性和安全性還是在限制范圍內。近日,俄羅斯聯邦通信、信息技術
推理模型競賽又添新玩家。1 月 15 日,科大訊飛對外發布首個基于全國產平臺訓練的深度推理模型訊飛星火 X1,該模型憑借更少的算力,實現了業界一流的效果,多項指標國內第一,并率先應用于真實場景。
目前,市面上的推理模型眾多,但各家的側重點并不相同。比如 DeepSeek 著重強調其通過強化學習訓練,可以對外展現更長的思維鏈。通義團隊多次強調 QwQ 的深度自省能力,模型在思考過程中會質疑其自身假設,審視推理過程。月之暗面則更強調 k0-math 的數學能力,稱其數學能力可以與 OpenAI 的 o1 系列模型媲美。
科大訊飛最新發布的推理模型 X1 多項指標實現國內第一。發布會上,科大訊飛展示了訊飛星火 X1 解答高考題、AIME 競賽題以及高中奧賽題的表現。
X1 不僅準確給出答案,還可以對解題思路和步驟進行詳細拆解,充分展現深度推理模型的三大典型特征:一、化繁為簡,將復雜問題分步拆解簡化;二、進行自我探索和反思驗證;三、基于答案正確與否的優質反饋信息進行強化訓練。
以一道 2024 年全國高中聯合數學競賽的無窮等比數列求和問題為例,分別在網頁端提問訊飛星火 X1 與 DeepSeekV3、Kimi 中的最新推理模型。

三者均展現出當下推理模型的典型特征,比如能夠針對對復雜問題進行分步拆解,也會在求解過程中不斷進行自我反思驗證。
不過,相較于訊飛星火 X1 在解答過程中動態展示思維步驟不同,DeepSeek 對外強調的思維鏈條有些過長,一定程度上影響了用戶與模型的交互。Kimi 則是將思考過程與模型回答融為一體,卻沒有給出一個總結性的解題步驟,不夠直觀。
在回答準確率上,我們引用包括小初高(含競賽)、大學(含競賽)、AIME、MATH500 等多項數學考試測試數據進行對比。其中,訊飛星火 X1 多項指標均獲國內第一。在多個中文考試測試的比拼中,訊飛星火 X1 得分都超過 DS-R1-Lite-Preview、QwQ-32B-Preview、K1-math 等眾多推理模型,中文數學能力國內第一。

更難能可貴的是,這份成績還是基于全國產算力平臺得來的。和市面上常見的其他模型不同,訊飛星火 X1 是目前全國產算力平臺上唯一的深度推理模型,用更少的算力,實現了業界一流效果。
這樣的成績十分難得。一直以來,訊飛星火都堅持全國產化路線,訊飛星火至今仍然是國內唯一基于全國產算力平臺的大模型。但推理模型的訓練與大語言模型有諸多不同,仍然面臨不少挑戰。科大訊飛迎難而上,攜手華為成功攻克了訓練推理強交互、高吞吐推理優化以及國產算子優化等一系列難題,最終成功基于全國產算力平臺訓練出深度推理模型 X1。
之所以訊飛星火 X1 一出世就能在多項數學測試中取得亮眼成績,和此前訊飛星火著重提升的數學能力不無關系。事實上,一直以來訊飛星火都是數學能力最強的大模型之一。此前,訊飛星火 4.0Turbo 就在數學和代碼能力上實現對 GPT-4o 的超越,完成了超長思維鏈、樹搜索和自我反思評價等算法的驗證。
去年高考期間,多家媒體和專業人士用高考數學題對市面上的大模型進行測評比試,訊飛星火表現出色,領先一眾同行。
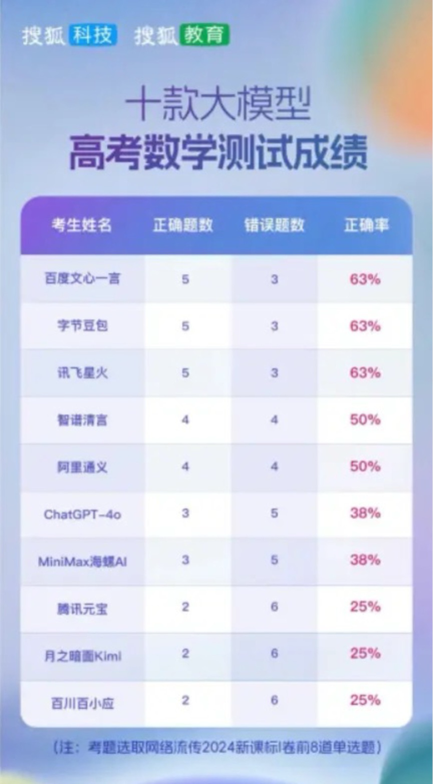
在搜狐科技針對國內十余家大模型的高考數學能力評測中,訊飛星火、文心一言、豆包均以63% 的正確率位列第一梯隊,智譜清言、阿里通義則以50% 的正確率位居第二梯隊,其他大模型相對落后。
這次著重提升了深度推理能力的 X1,則是將訊飛星火一直見長的數學能力再度提升一個維度。相較于此前的大語言模型,訊飛星火 X1 從訓練方法、訓練數據乃至架構上都有所不同,數學和推理能力顯著提升。
技術迭代之外,科大訊飛率先將推理模型應用到教育、醫療等真實剛需場景之中。搭載了星火 X1 的高中數學智能教師助手,已被一線教研員和教師用來解答高中數學創新題和考試題。在醫療場景下,X1 的相關技術和策略也取得了初步驗證成效,可使得專科輔助診斷和復雜病歷內涵質控的準確率均達 90%。
大模型時代的迭代速度遠超以往,一家公司的領先往往只能持續數月乃至數周,稍有不慎就會被后來者超越,此次訊飛星火 X1 出道即“巔峰”也正說明了這一點。唯有不斷從底層攻難克堅,真正從源頭實現自主可控,才能在日益飛速技術迭代立于不敗之地。
本文鏈接:http://www.www897cc.com/showinfo-26-126062-0.html強強 PK 國產勝,訊飛星火 X1 碾壓 DeepSeek
聲明:本網頁內容旨在傳播知識,若有侵權等問題請及時與本網聯系,我們將在第一時間刪除處理。郵件:2376512515@qq.com
Copyright ? 2016-2023 天津谷騏科技有限公司 版權所有 sitemap.xml
違法及侵權請聯系:2376512515@qq.com 津ICP備18001702號
 津公網安備 12010102000574號
津公網安備 12010102000574號